It’s important to understand the full context relating to social media statistics before you act on them.
The Stat
I came across this stat the other day:
91 per cent of mentions [on social media] come from people with fewer than 500 followers.
The implication in the source blog post and whitepaper was:
When it comes to your social media strategy, don’t discount the importance of brand mentions by Twitter users with low follower counts.
It’s complicated
Follower numbers shouldn’t be the be all and end all when it comes to defining your social media strategy. Agreed.
For a start, where influence is concerned, relevance, proximity, context and other factors are crucial. And followers is a very simplistic metric and depending on how they use social platforms, may have little in common with a person’s real potential for influence.
Also, even if the mention itself doesn’t influence anyone, simply the knowledge that an individual has shown an interest in your brand in some way is potentially of value.
But while sympathising with the inference drawn, I think the statistic and its underlying data would benefit from some numerical context to better understand their implications.
N.B. I’ve focussed on Twitter in this analysis as that’s where the majority of the data in the particular research apparently came from.
Analysis
Given the stat focuses on accounts with less than 500 followers, let’s split Twitter into two groups:
– Low Follower Group – Less than 500 followers.
– High Follower Group – 500 or more followers.
And then let’s look at two relevant areas – Impressions and Retweets.
Impressions
Who could have seen brand mentions by each of these groups and potentially been influenced by them?
To calculate this we need to know the following for each group:
– Average number of followers.
– Impression rate.
Average followers
I used this estimated distribution of follower numbers across Twitter users*, combined with Lissted‘s data on nearly 2 million of the most influential accounts, to calculate a weighted average of the number of followers each group is likely to have.
Results:
– Low Follower Group – 100
– High Follower Group – 8,400
Impression rate
Every time you tweet only a proportion of your followers will actually see it. For many users this proportion could be less than ten per cent. The “impression rate” represents the total number of impressions generated by your tweet, divided by your follower number.
It only includes impressions on specific Twitter platforms – web, iOS app and Android app. This means impressions in applications like Hootsuite and Tweetdeck don’t count.
The rate is also complicated by retweets. The rate calculated by Twitter Analytics includes impressions that were actually seen by followers of the retweeting account, who may not follow you.
I’ve tried to look at retweets separately below, so for the purpose of this analysis I’m looking for impression rates without the benefit of retweet amplification.
On this basis I’ve assumed an impression rate of ten per cent for the Low Follower Group and five per cent for the High Follower Group. These assumptions are based on various articles estimating impression rates in the range of 2-10%. For the sake of prudence I’ve used a lower rate for High Follower accounts on the assumption that they could have a higher proportion of inactive and spam followers.
We can now calculate the proportion of total impressions related to each group as shown in this table:
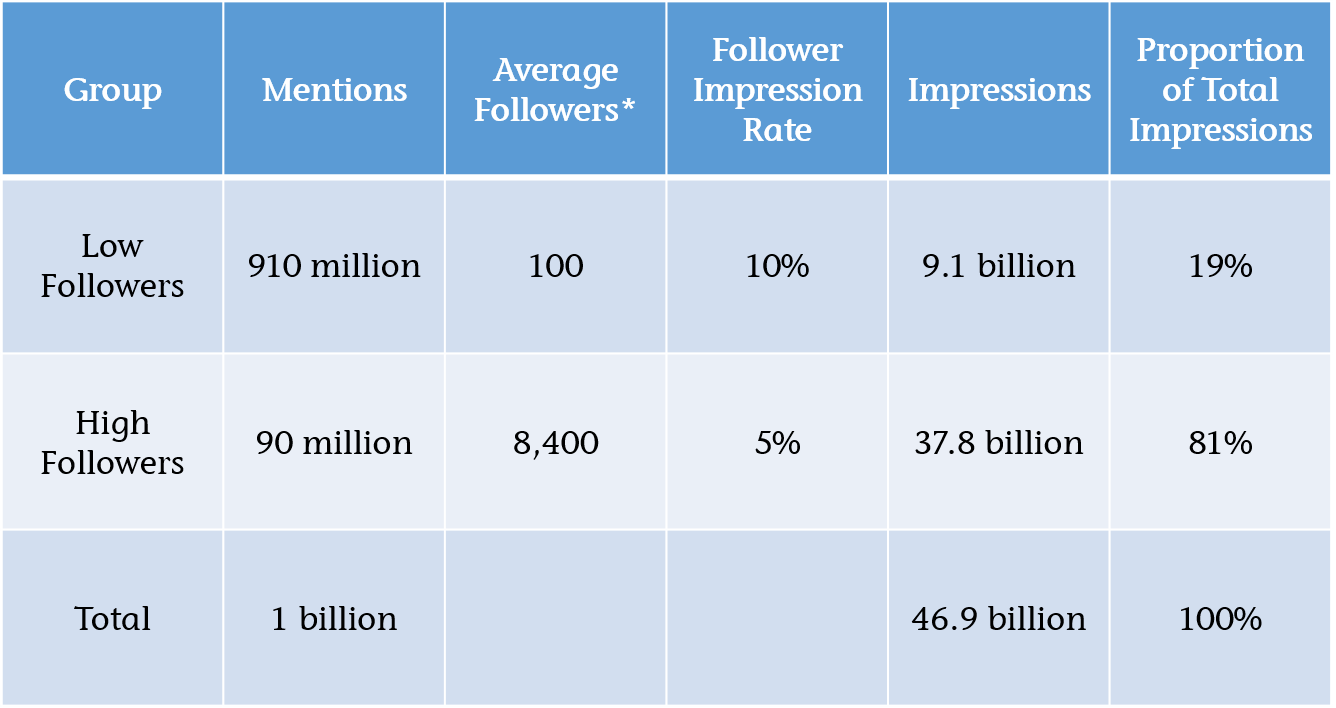
Finding: only 19 per cent of impressions relate to the Low Follower Group.
Quite simply the difference in reach of the High Follower accounts (84x higher – 8,400 v 100) more than offsets the difference in volume of mentions by the Low Follower Group (only 10x higher – 910 v 90).
For the Low Follower Group to even represent 50 per cent of the total impressions we’d need to assume an impressions rate for this group that is over 8x higher than for the High Follower Group e.g. 42% v 5%.
Though I suspect there may be a difference, is it really likely to be that much?
Retweets
Next we need to consider if any of the brand mentions were retweets. If so were the original tweets more likely to be by accounts with high or low followers?
A lot of retweets by volume are by accounts with low followers. That’s just common sense because the vast majority of Twitter users have low follower numbers. But when we’re exposed to a retweet it’s the original tweet that we’re exposed to. This is the very reason why Twitter includes the resulting impressions in the Impression rate (I’m assuming automatic retweets, not manual ones).
To understand this better I analysed a sample of over six million tweets tracked by Lissted over the last two months that were retweeted at least once. The sample included tweets by 1.27 million different accounts and collectively these tweets received over 200 million retweets in total.
Of these six million tweets, 0.6% of them (c.39,000) accounted for two thirds of the total retweets generated.
And 99 per cent of these “top tweets” were by users with 500+ followers.
Finding: a high proportion of retweets are of users with High Followers, even if many are by users with Low Followers.
Conclusion
Mentions relating to accounts with higher than 500 followers appear more likely to:
– represent the majority of initial impressions; and
– generate the majority of any resulting retweets.
In other words it’s high follower accounts that are more likely to be the source of the majority of the brand mentions that people are exposed to on Twitter.
Caveat
As I said at the start the purpose of this analysis is simply to give some proper context to an isolated statistic. Assessing the impact and actions you should take due to mentions of your brand requires consideration of a lot more factors than simply numerical exposure.
It could be the case that high follower tweets make up the vast majority of the mentions people are exposed to, but factors like trust, context, proximity and relevance could lead to mentions by low followers having more influence on business outcomes.
The key is to properly understand who is talking about you and why, and not base decisions on sweeping statistics.
*N.B the follower distribution analysis is from Dec 2013, but as Twitter hasn’t grown a huge amount in the last year, it seems reasonable to assume its validity. Happy to share my detailed workings with anyone who’s interested.






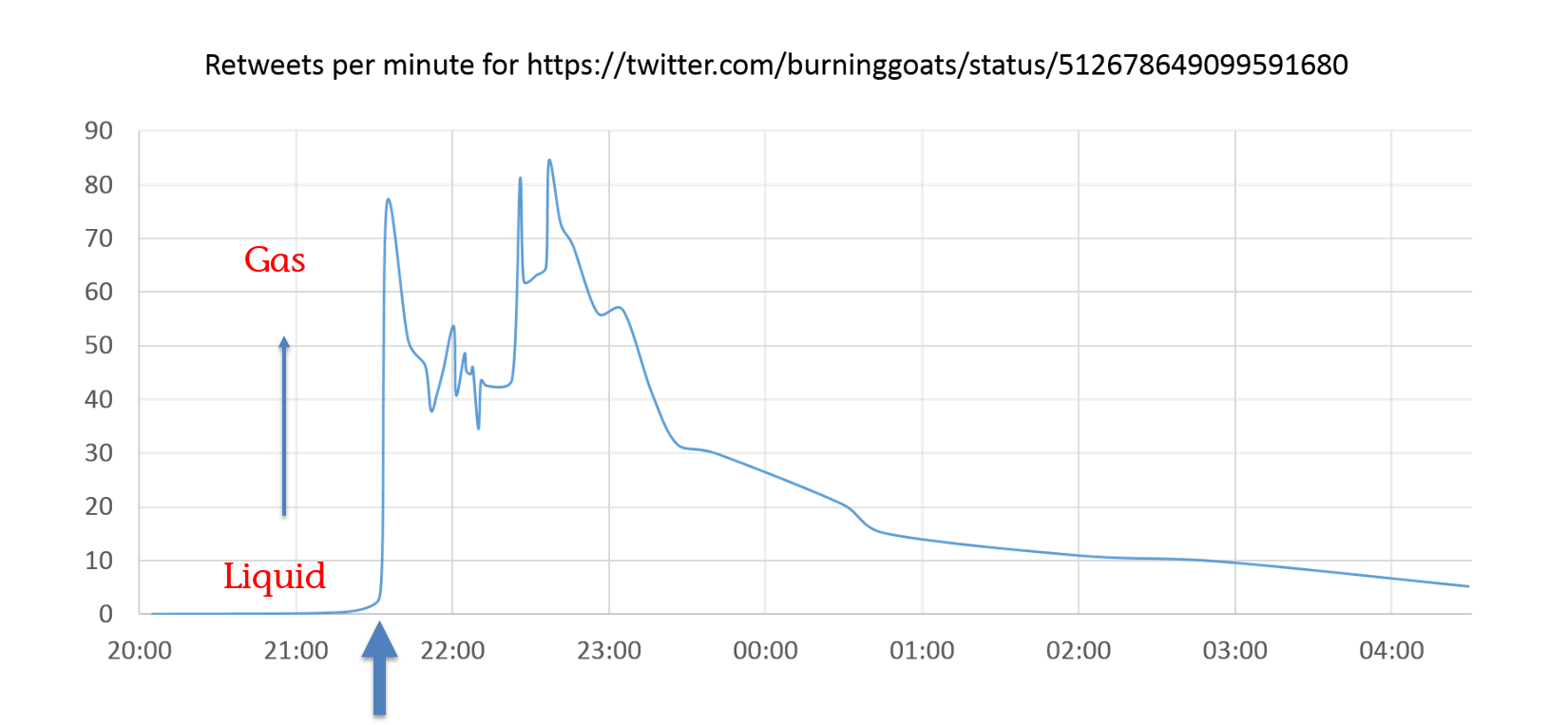
 At 21:31 the tweet is retweeted by @BefairSports, an account that doesn’t follow @BurningGoats.
At 21:31 the tweet is retweeted by @BefairSports, an account that doesn’t follow @BurningGoats.  He also retweets the story at 21:33 and immediately following this combination we see a massive spike in retweet activity.
He also retweets the story at 21:33 and immediately following this combination we see a massive spike in retweet activity. 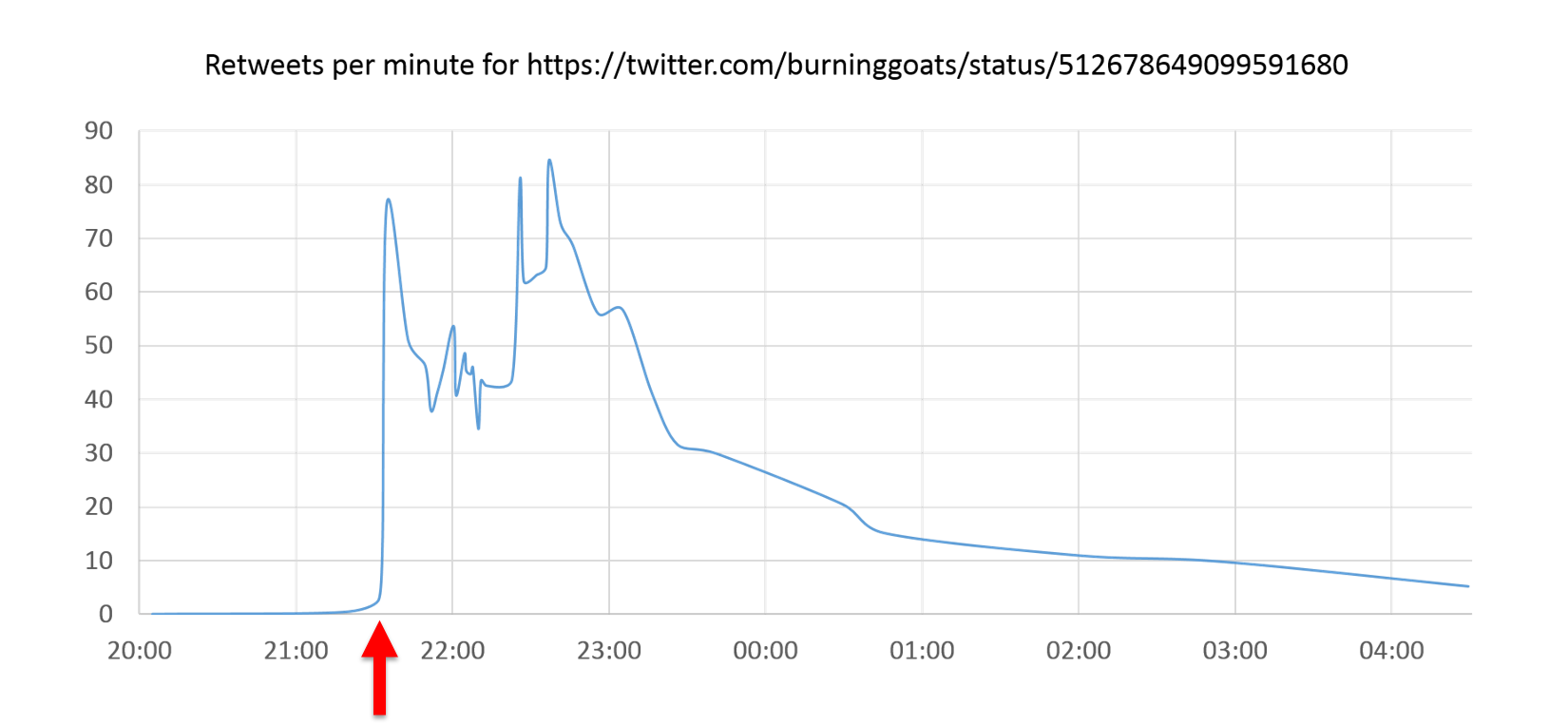
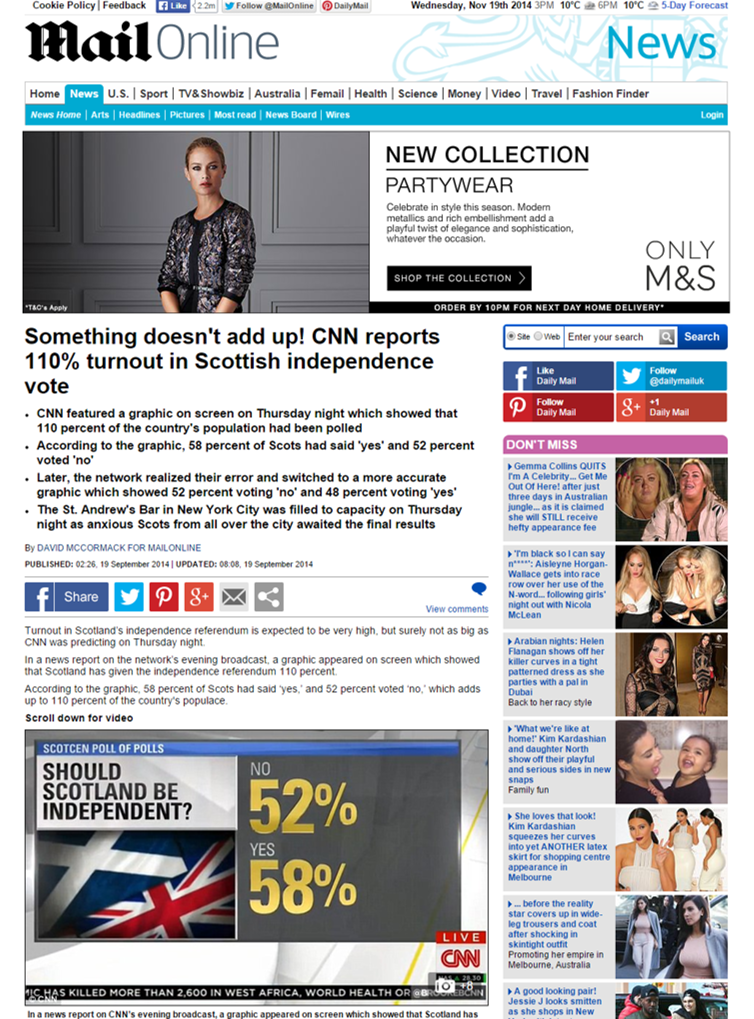

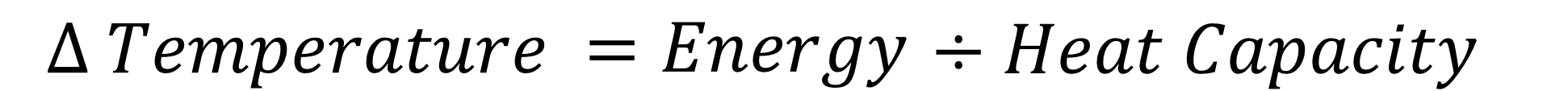

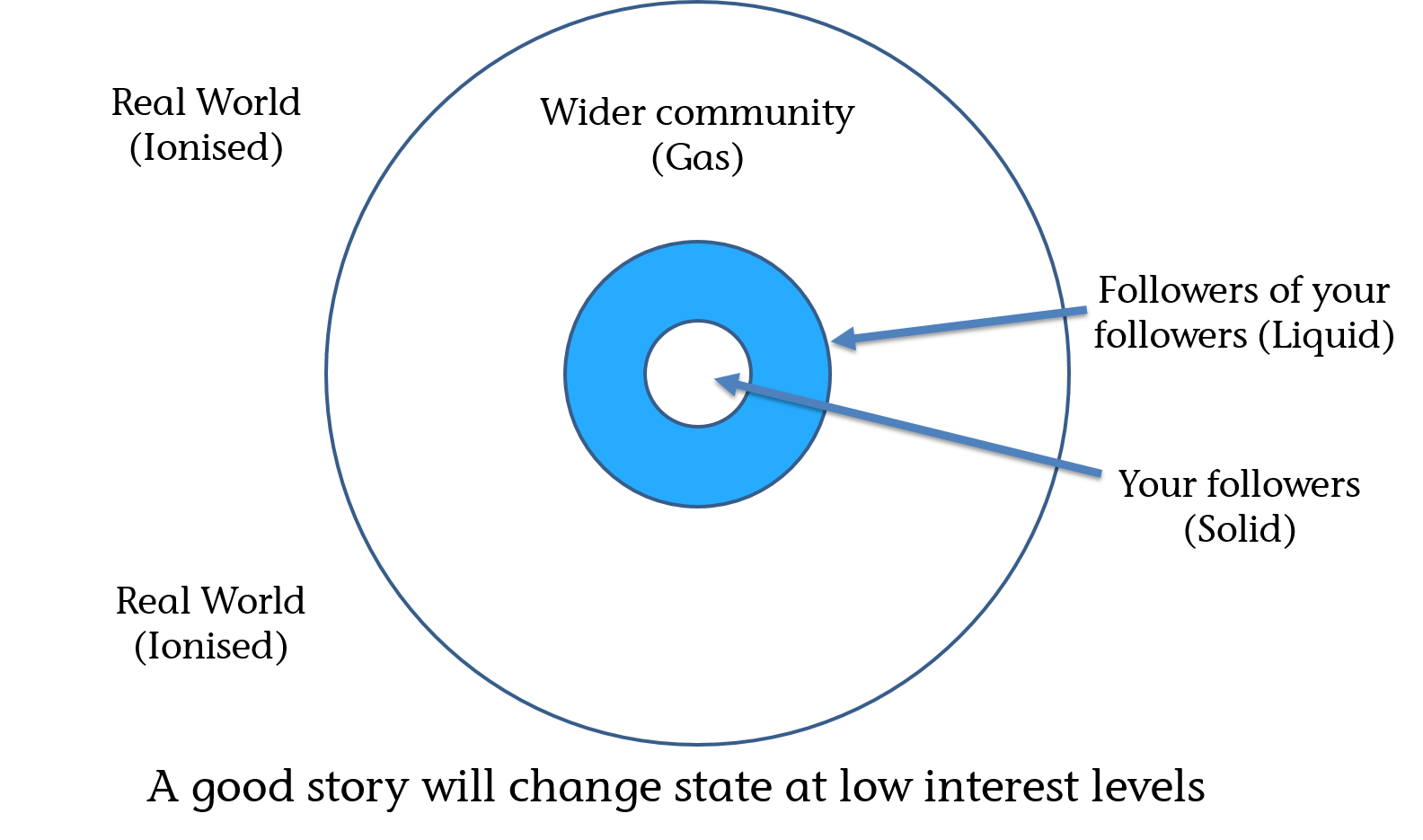
 There is also a fourth state that matter can take. When a gas is heated sufficiently it will ionise and form plasma (the most abundant material in the universe). Different materials go through phase changes at different temperatures.
There is also a fourth state that matter can take. When a gas is heated sufficiently it will ionise and form plasma (the most abundant material in the universe). Different materials go through phase changes at different temperatures.



{kind=link}