Twitter has invested $2.2bn in research and development over the last three years. But with growth in net revenue slowing considerably in 2016, it appears this sizeable investment is no longer paying dividends. Data for this post can be found here.
As Twitter’s revenue growth slows and its share price continues to slide, it’s not surprising to find the company’s costs being scrutinised. Earlier this week Techcrunch looked at executive pay and the remuneration of CFO/COO Anthony Noto in particular.
Research and development expenditure is a key area for a technology company like Twitter. You would expect it to be a significant cost, and sure it enough it is. You would also expect to see a significant return from such investment in user growth and ultimately in revenue. Twitter’s lack of user growth has been widely discussed so I’ve focussed on the $s.
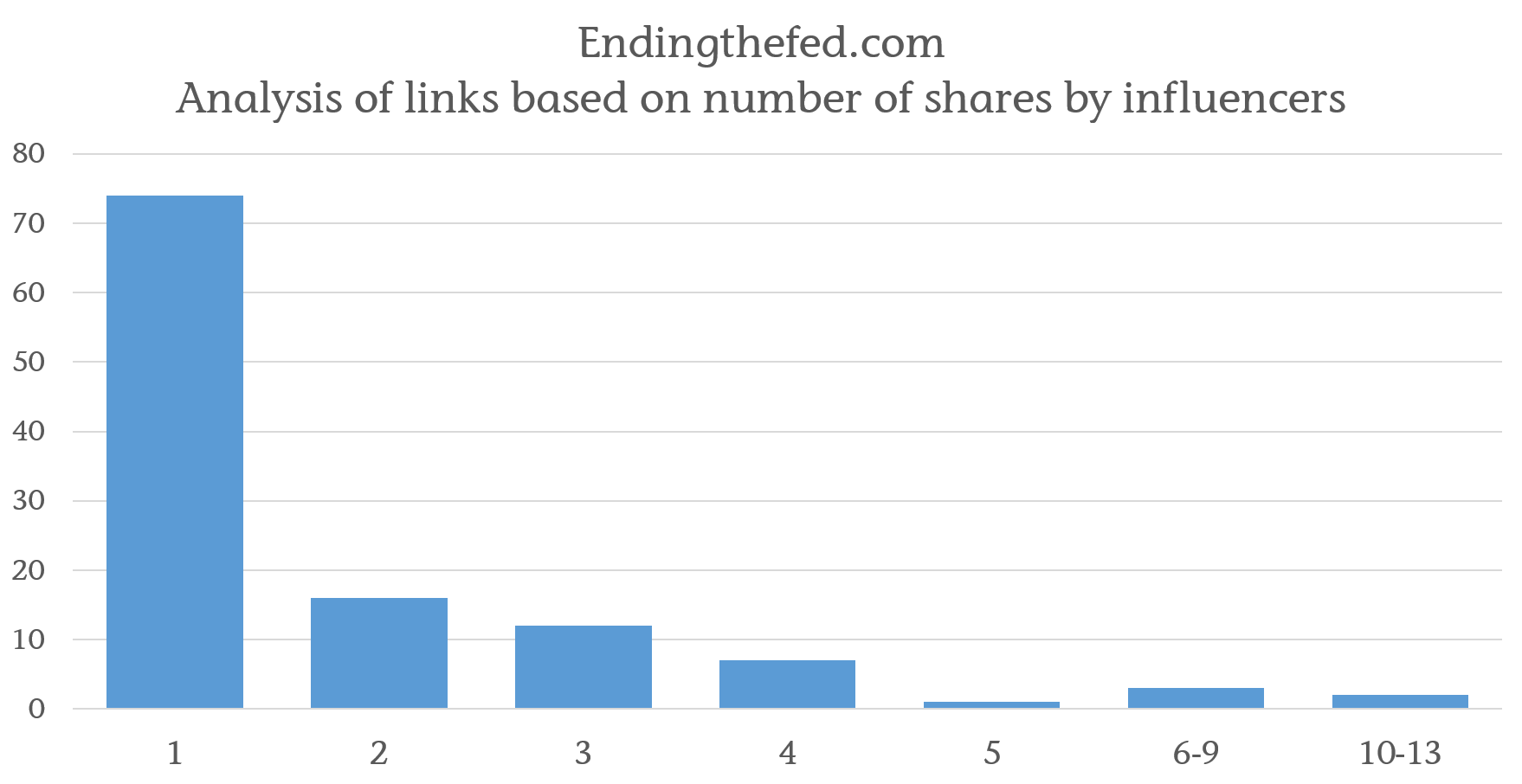
Twitter’s 2016 R & D Performance
Twitter spent $713m on research and development in 2016.
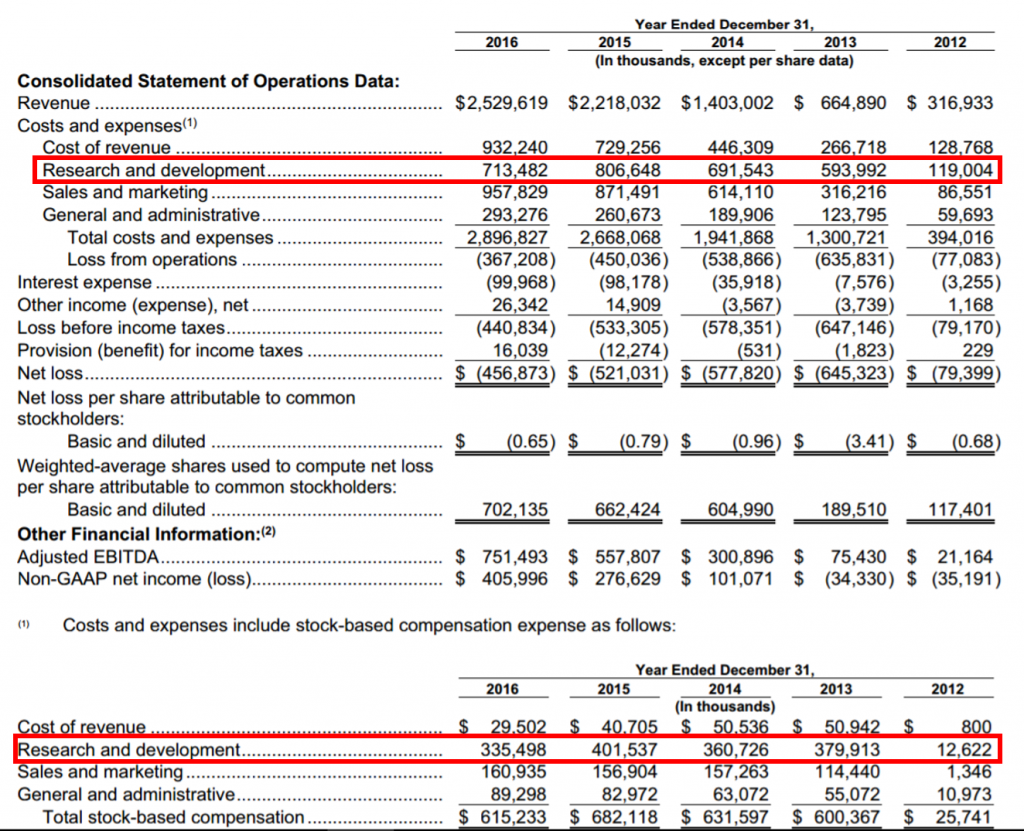
At the same time its net revenue (revenue minus the direct costs of earning that revenue) grew by $109m, a 7.3 per cent increase on 2015.
That represents $0.15 of additional net revenue for every $1 spent on R&D.
Facebook’s performance 10x better
To put that in context Facebook’s equivalent numbers were:
- R & D spend – $5,919m
- Net revenue growth $8,788m.
- $1.48 of additional net revenue for every $1 spent on R&D.
If Twitter had achieved the same level of net revenue growth for every $ spent on R&D its net revenue would have risen by over $1bn in 2016 ($1.48 x $713m = $1,055m).
This would have represented a 70.8 per cent increase in net revenue versus the actual growth achieved of 7.3 per cent.
Decline in Twitter R & D returns
As the graph below shows, 2015 and 2014 were considerably better by this metric.

Twitter achieved $0.66 of net revenue increase per $ in R&D spend in 2015 and $0.81 in 2014.
These figures were similar to those achieved by Alphabet (Google), though still only half (2014) and two thirds (2015) of Facebook’s.
These numbers show that matching Facebook’s 2016 performance of $1.48 revenue/$ R&D was probably too much of a tall order.
However even if Twitter’s 2016 performance had only been equal to its own 2015 figure the company would still have seen a rise in net revenue of $470m ($0.66 x $713m), $361m more than was actually achieved. This would have meant a growth rate of 31.6 per cent.
You can imagine the significant impact on the company’s share price that a stronger growth story like this would have.
So R&D is still being heavily funded, but revenue growth is fast disappearing. This begs the questions, where, in who and in what are these funds being invested?
Share based compensation
Another factor here is Twitter’s R & D staff are the single biggest recipients of share based compensation (SBC). Anyone unfamiliar with share based compensation please skip to the end of the post for a brief explanation of how it works before reading further.
In the last three years Twitter’s total share based compensation expense has totalled $1,929m and has exceeded the total adjusted EBITDA generated by the company ($1,610m).
Effectively all the underlying profit generated (and more) since its IPO has been invested in remunerating employees and officers.
Research and development SBC has totalled $1,099m over the last three years. This represents half of the $2.2bn invested in R&D and shows how crucial share based remuneration is to Twitter’s strategy for attracting and retaining product and engineering talent.
The problem is that this represents a transfer of value from shareholders to R&D staff of over $1bn since the start of 2014. Meanwhile any innovation and improvements made are having a declining impact on revenue growth, resulting in a reduction in Twitter’s value of $25bn over the period.
Not what you’d call a great deal for shareholders.
What does this mean?
I can see two key factors at work here:
- Competition for talent – Twitter needs to attract the same quality of people who could work at Facebook, Google et al. It therefore needs to offer competitive remuneration packages. Share based compensation has apparently formed a key part of this to date.
- Creative block – lack of successful new ideas, innovation and improvements to drive revenue growth.
Implying the following question:
Should Twitter be getting more out of its R&D resources or are even these talented individuals unable to add significant value to the platform?
If the former, then this is a management issue which needs addressing and fast.
If the latter then the company should be looking outside of its own teams for ideas and innovation and allocating funds accordingly.
Either way, if it continues to invest huge sums in R&D without significant improvement in net revenues, then the company’s declining value appears unlikely to turnaround.
Share based compensation expense – an explanation
In a company’s accounts share based compensation (SBC) expense represents value given to employees of the company in the form of shares or options.
It’s calculated in various ways, but in simple terms it’s equal to:
SBC expense = Market value (of shares/options provided) – Amount paid by employee
Share based compensation generally forms part of an employee’s remuneration package to attract new joiners, motivate them to create value and/or improve retention.
SBC is a non cash expense, however because it relates to the creation of new shares – either immediately or potentially in the future when options become exercisable – its effect is to dilute existing shareholders. Again in simple terms this dilution is equal to the value of the expense.
Shareholders therefore expect to see a return on this investment greater than the value that they have been diluted by.
Example:
Note this is a highly simplified example, but it should help to get the gist.
Today ABC Company has a market capitalisation (the value of its equity to its shareholders) of $1bn.
It gifts shares to a group of highly sort after new employees who it believes will be instrumental in creating a new product.
The SBC expense of these shares is $10m at the point they are gifted i.e. 1% of its equity value.
The new employees are prohibited from selling the shares for a period of one year.
All things being equal the existing shareholders now only own 99% or $990m of the company.
A year later the company is valued at $1.2bn, with the $200m increase in value being wholly attributed to the success of the new product created by the team.
The shareholders 99% is therefore worth $1.188bn representing a gain of $188m.
The new joiners can now sell their shares worth $12m ($10m value when they were granted plus 1% of the increase of $200m in the overall value of the company).
Everyone’s a winner. The company didn’t have to find any cash. The new employees have banked $12m (less associated taxes) and shareholders have seen the value of their shares rise by nearly 19%.
Note: I do not own any shares in Twitter, Facebook or Alphabet. All analysis is based on publicly available information from Annual Reports, SEC filings and Proxy Statements.